The Curse of Local Minima: How to Escape and Find the Global Minimum
There is no easy solution to the curse of local minima, but there are techniques that can help.
In machine learning, local minima and global minima are two important concepts related to the optimization of loss functions. A loss function is a function that measures the error between a model’s predictions and the ground truth. The goal of machine learning is to find a model that minimizes the loss function.
A local minimum is a point in the parameter space where the loss function is minimized in a local neighborhood. A global minimum is a point in the parameter space where the loss function is minimized globally.

In general, it is not possible to find the global minimum of a loss function analytically. Instead, machine learning algorithms use iterative optimization methods to find a local minimum.
One common iterative optimization method is gradient descent. Gradient descent starts at a random point in the parameter space and then iteratively updates the parameters in the direction of the negative gradient of the loss function. The negative gradient points in the direction of the steepest descent, so gradient descent will eventually converge to a local minimum.
However, there is no guarantee that the local minimum found by gradient descent is the global minimum. In fact, it is possible that gradient descent will get stuck in a local minimum that is not the global minimum.
There are a number of techniques that can be used to avoid getting stuck in local minima. One technique is to use a different optimization algorithm, such as simulated annealing or genetic algorithms. Another technique is to use a regularization term in the loss function. Regularization terms penalize the model for having large parameters, which can help to prevent the model from overfitting the training data and getting stuck in a local minimum.
Some Mathematical Examples
Let f(x) be a loss function. A local minimum of f(x) is a point x* such that f(x*) < f(x) for all x in a neighborhood of x*. A global minimum of f(x) is a point x* such that f(x*) < f(x) for all x in the domain of f(x).
Here is an example of a loss function with two local minima and one global minimum:
f(x) = x² - 2x + 1
The local minima of f(x) are x = 1 and x = -1. The global minimum of f(x) is x = 0.
Here is an example of a loss function with no local minima:
f(x) = x^3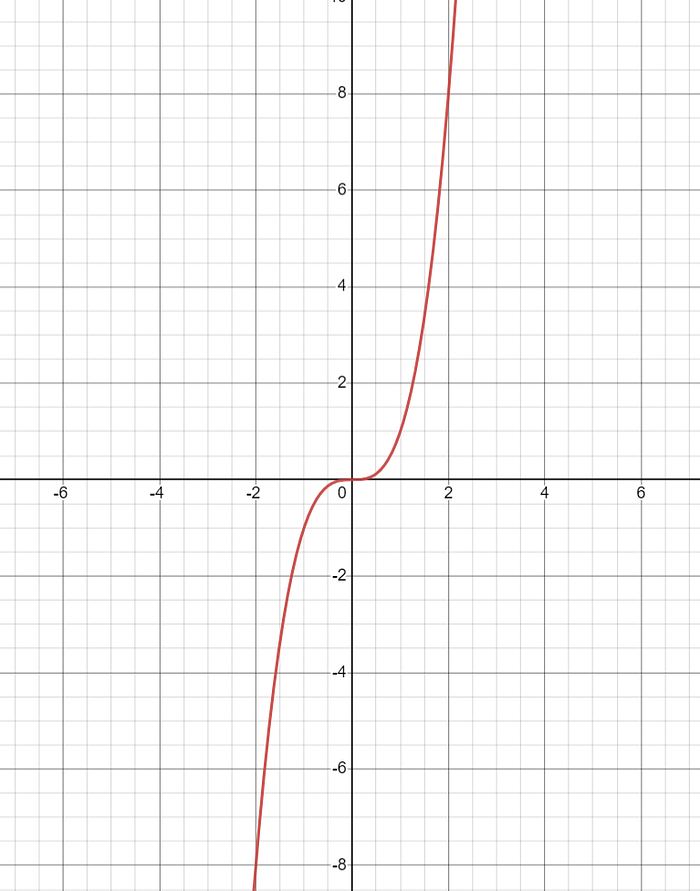
This function has no local minima because it is always increasing.
In machine learning, it is important to find the global minimum of the loss function. This is because the global minimum represents the best possible model for the data. However, it is not always possible to find the global minimum. In these cases, it is important to find a local minimum that is close to the global minimum.
How To Deal With Local Minima
There are a few different ways to avoid local minima in gradient descent.
- Random restarts: This involves randomly re-initializing the optimization algorithm and starting over. This can help to escape local minima by starting the algorithm in a different location.
“Local minima are a common problem, but there are ways to avoid them.” — Michael Nielsen
- One common approach is to use a stochastic gradient descent (SGD) algorithm. SGD works by randomly sampling a subset of the data points at each iteration, and then using the gradient of those data points to update the model parameters. This helps to prevent the algorithm from getting stuck in a local minimum, because it is constantly exploring different parts of the loss landscape.
- Another approach to avoiding local minima is to use a momentum algorithm. Momentum works by adding a fraction of the previous gradient to the current gradient. This helps to smooth out the path of the algorithm, and makes it less likely to get stuck in a local minimum.
- Nesterov momentum: This is a variation of momentum that can be more effective at escaping local minima.
- Simulated annealing: This is a technique that uses simulated annealing to escape local minima.
- Bayesian optimization: This is a technique that uses Bayesian optimization to escape local minima.
- Ensemble learning: This is a technique that uses ensemble learning to escape local minima.
- Finally, you can also use a regularization technique to avoid local minima. Regularization works by adding a penalty to the loss function that is proportional to the size of the model parameters. This helps to prevent the model from overfitting the training data, and can make it less likely to get stuck in a local minimum.
There are a few ways to know if your model is stuck in a local minimum. One way is to look at the loss function. If the loss function is not decreasing after a certain number of iterations, it is likely that the model is stuck in a local minimum.
“The global minimum is the best possible solution, but it’s not always easy to find.” — Andrew Ng
Another way to know if your model is stuck in a local minimum is to look at the model parameters. If the model parameters are not changing after a certain number of iterations, it is likely that the model is stuck in a local minimum.
If you think that your model is stuck in a local minimum, you can try one of the following:
- Change the learning rate: A smaller learning rate may help the model to escape from the local minimum.
- Use a different optimization algorithm: A different optimization algorithm, such as SGD or momentum, may be more effective at avoiding local minima.
- Add regularization: Regularization can help to prevent the model from overfitting the training data and can make it less likely to get stuck in a local minimum.
It is important to note that there is no guarantee that you will be able to avoid local minima. However, by using the techniques described above, you can increase your chances of finding the global minimum.
Here are some statistical facts about local minima:
- Local minima are common: In most cases, there are many local minima in the loss landscape. This means that it is very likely that a model will get stuck in a local minimum, unless you take steps to avoid it.
- Local minima can be very different: The loss of a local minimum can be very different from the loss of the global minimum. This means that a model that is stuck in a local minimum may not be very accurate.
- It is difficult to find the global minimum: Finding the global minimum is a very difficult problem. Even with the best optimization algorithms, it is often not possible to find the global minimum.
Overall, local minima are a major challenge in machine learning. However, by using the techniques described above, you can increase your chances of finding the global minimum.
Thank you for reading my blog post on The Curse of Local Minima: How to Escape and Find the Global Minimum. I hope you found it informative and helpful. If you have any questions or feedback, please feel free to leave a comment below.
I also encourage you to check out my portfolio and GitHub. You can find links to both in the description below.
I am always working on new and exciting projects, so be sure to subscribe to my blog so you don’t miss a thing!
Thanks again for reading, and I hope to see you next time!
